
Have you ever wanted to do any of the following from a Contact Center application?
- Read a schedule from a local document, rather than having to use script editor to edit schedules
- Be able to load a schedule from a web server, so you didn’t even need to touch you CCX server
- Bring in external data without UCCX Premium
- Bring in external data from a database there isn’t a driver for
All these and more can be done by reading XML formatted data either stored in the local repository, or served from an external web server, and retrieved using the Create URL Document or Make REST Call steps. Since you are able to read from a web server, any web programing language, like PHP, ASP, or JSP, could be used to retrieve and format the data.
Once UCCX has the XML formatted data, the Get XML Document Data step uses the XPath syntax to get data out of the document. This is a powerful syntax for reading data from XML formatted documents, as we will explore here.
In this post, we will use the Make REST Call step to retrieve information from the REST interface on the UCCX server, which provides easy access to a remote source of XML formatted data.
For the first part, we will retrieve the name for a skill that we have the SkillID for. This is made easier in the UCCX REST API, because adding the SkillID to the end of the URL returns only that skill, so we only need to specify the value we want returned, and don’t have to try to find it among multiple datasets.
The first step is to use the Make REST Call step to read the response into a string variable.
Create the following string variables (names used in the example in parentheses):
- Username and password (strUsername and strPassword)
- Response (strXML)
- Status Code (strCode)
- Status Detail (strDetail)
- Skill Name (strSkillName)
And a document variable (XMLDocument)
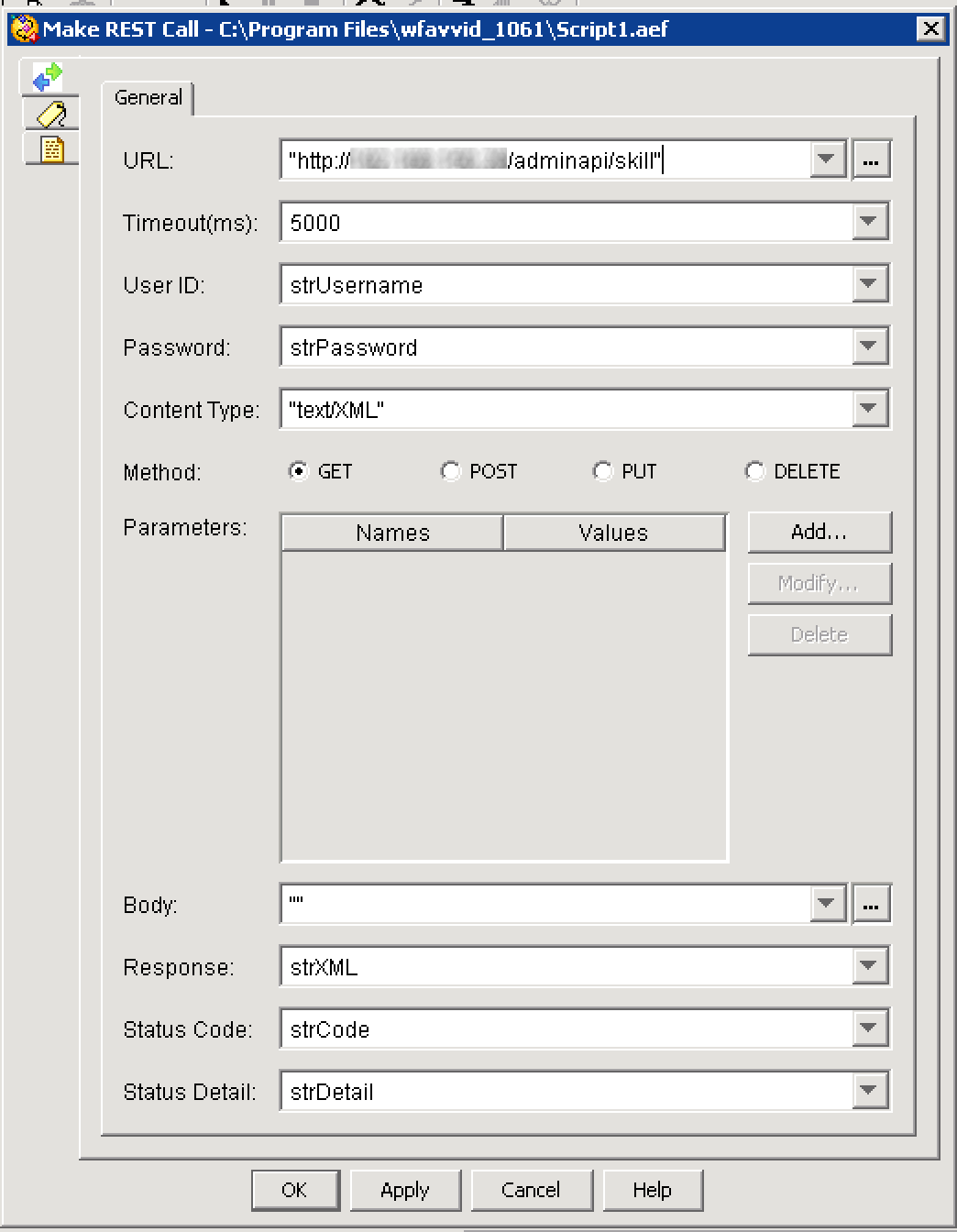
Add the Make REST Call step, and configure as follows:
- URL: http://<uccx server address>/adminapi/skill/2 (the /2 is the skillID, this will only return the specified skill. You may need to use a different number based on the skills configured on your server.)
- Timeout: 5000
- User ID: strUsername (or your username variable)
- Password: strPassword (or your password variable)
- Content Type: “Text/XML”
- Method: GET
- Body: Empty quotes
- Response, Status Code and Detail: the variables created above.
Under the output branches (successful and unsuccessful) we could add error checking and handling, but for this example we will just put the XML parsing logic under success, and a label called “Unsuccessful” under the unsuccessful branch for debugging purposes.
Before we parse the data, it needs to be placed in an XML document, so using the document variable we created earlier, assign the value of the returned string to it, then use the create XML Document step to correctly format it for XML reads. The Create XML Document step can use the same document variable as the input and output, as in this case. It will reformat the data to what is needed for the Get XML Document Data step.
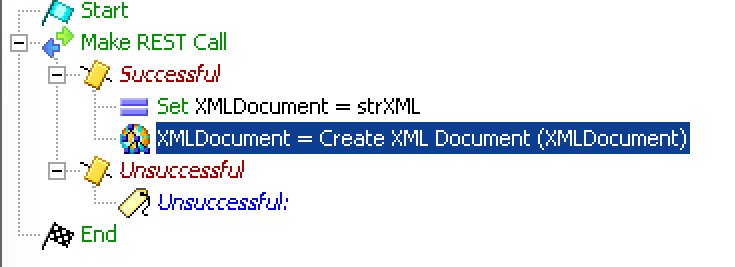
The next step is the one we are focusing on: Get XML Document Data. This step takes a document, and a string that is the XPath statement that we will use to parse the data we are looking for.
In the first example we will look at is relatively simple, we will parse the name for a skill we know the number for. The data looks like this:
<skill>
<self>http://192.168.150.28/adminapi/skill/2</self>
<skillId>2</skillId>
<skillName>Route</skillName>
</skill>
This is the response to a REST call requesting skill 2 on my lab UCCX server (http://<server>/adminapi/skill/2). In this case, the selection of which skill to look at was made in the original request by adding the “/2” to the URL, so we do not have to select which skill we want in the XML query.
To extract the skillName from the XML, there are two simple XPaths we can use:
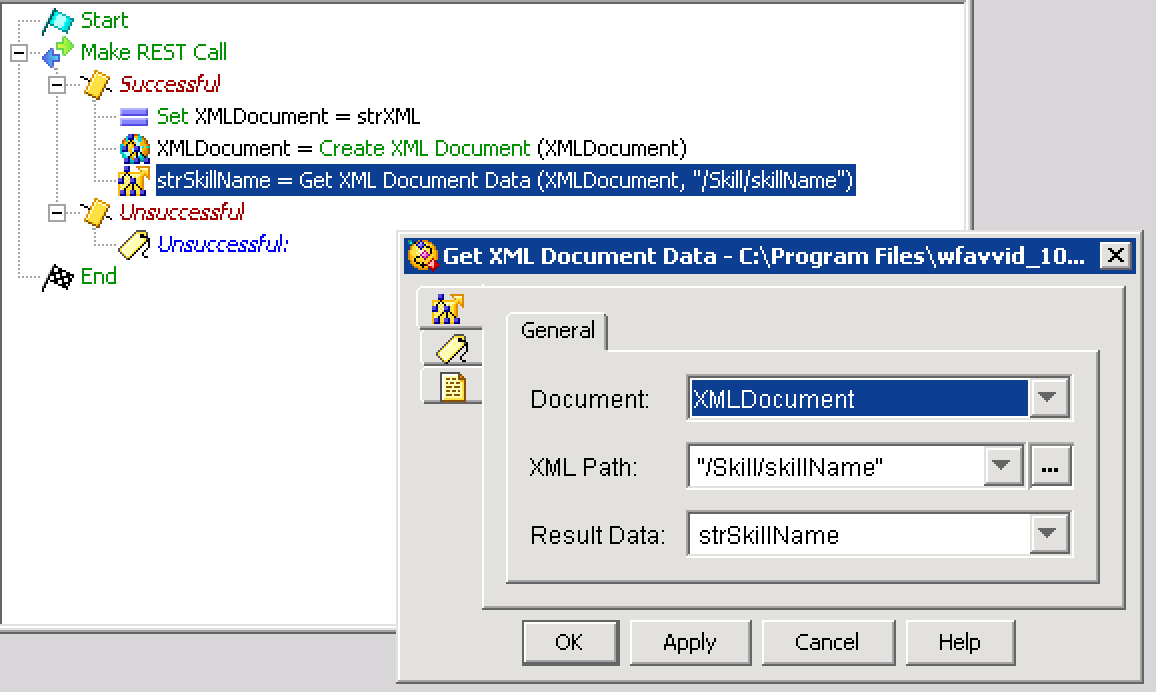
/Skill/skillName
This option provides an exact path to the data we are looking for, starting from the root node. If more than one possible path exists, the first available path will be used. The other option is to use a path with a double forward slash, and the final node name, or a sub path:
//skillName
This finds the first node called skillName, and returns the data. In this case it will find the first instance of skillName, and return the value. In the document we are working with, this would be acceptable, but it could lead to unexpected results with files that contain more data, like the next example.
You can use the debugging controls in Script Editor to step through the script, and see the variables change to verify the script is working. Try both versions of the XPath and make sure they are working as expected.
Now to look at a little more complex example. If you do not specify a skillID in the URL, it will return all the skills configured on the server:
<skills>
<skill>
<self>http://192.168.150.28/adminapi/skill/2</self>
<skillId>2</skillId>
<skillName>Route</skillName>
</skill>
<skill>
<self>http://192.168.150.28/adminapi/skill/3</self>
<skillId>3</skillId>
<skillName>Switch</skillName>
</skill>
<skill>
<self>http://192.168.150.28/adminapi/skill/4</self>
<skillId>4</skillId>
<skillName>Blog</skillName>
</skill>
</skills>
Note that the root element also changes from skill to skills, with skill under it.
In this case, we want to be to retrieve the skillId of the skill named “Switch.” Since the UCCX REST API does not allow us to retrieve a single skill based on the name, we will retrieve “http://<server>/adminapi/skill,” which includes all the skills, and use XPath to query the data out of the file.
Change the Make Rest Call step in the script to remove the /2 in the URL.
There are several ways to perform this query. The most simple is to use an XPath like the following:
/skills/skill[skillName='Switch']/skillId
In this case, we specify the value of a sibling (an XML node under the same parent, in this case “/skills/skill”) with the [skillName=’Switch’] part of the query statement. Any of the siblings can be selected this way, for instance “/skills/skill[skillName=’Switch’]/self” will return the URL value. If you are using a string value, as we are here, the string is case-sensative.
Another way to do this would be to loop through all the nodes, until we found one that had a skillName of Switch. I won’t go into the entire looping logic here, but we want to create a counter, starting at 1, and use that to select the node, using one of the following paths:
/skills/skill[1]/skillName or //skill[1]/skillName
This will return the first value, you then increment 1 to 2, and loop through the query until a null value is returned. Why choose to do it this way? The values you are querying are case-sensitive, so you may want to take the value back into your script, convert the string to lower case, and then make the comparison. You could also use a loop like this to build an array.
A downside of the loop method is that UCCX sets a maximum number of steps that a script can run, to avoid runaway loops. You can change the maximum number of steps that a UCCX script can execute in AppAdmin > System > System Parameters, and then set the Max Number of Executed Steps value to the number of steps you want to allow a script to execute. Be careful adjusting this, since it is a safety mechanism to prevent a programming loop from crashing the server.
You can also create an XML formatted document, and upload it to the documents repository. To retrieve the document, use a document variable, and set the value to DOC[<docname>].
What have you used XML data reads for, and what do you think you might use them for in the future? Leave any comments or questions below.
How to get Attribute value of Node?
Merely interested, exactly what wp theme are you using since it seems awesome?
It’s called Weaver II
Nice article! With this info I was able to create a script where agents can call CUCCX to change their skill level, so that a supervisor isn’t annoyed every day.
Many thanks 🙂